5 Projekt: Implementierung von RSA
In diesem Kapitel sollen die zuvor entwickelten TVLInt-Zahlen für die Implementierung eines RSA-Verschlüsselungs-Systems eingesetzt werden.
5.1 Pflichtenheft
Wir wollen ein alltagstaugliches "Krypto-Programm" zur Ver- und Entschlüsselung von Texten bauen. Wir verwenden den RSA-Algorithmus, den wir schon aus einem früheren Kapitel kennen. Für den Betrieb unseres Krypto-Programms benötigen wir natürlich auch entsprechende Schlüssel. Diese sollen in einem gesonderten Schlüssel-Erzeugungs-Programm hergestellt werden. Es sind also im Wesentlichen die folgenden Aufgaben zu erledigen:
- Der Rechenkern des RSA-Verfahrens ist die "Modulo-Exponentiation", also die Berechnung des Terms "g^h mod n". Dabei sind g, h und n sehr große ganze Zahlen, also in unserem Fall TVLInt-Zahlen. Die Modulo-Exponentiation müssen wir noch implementieren, weil unsere TVLInt-Zahlen bisher nur die 4 Grundrechenarten beherrschen. Die entsprechende Prozedur soll in einer Unit "mRSATools.pas" zur Verfügung gestellt werden.
- Es muss ein Algorithmus implementiert werden, der sehr große Primzahlen produziert. Gesucht ist eine Prozedur, die eine beliebige Startzahl übergeben bekommt und dann eine Pseudo-Primzahl liefert, die mindestens so groß ist wie diese Startzahl. Auch diese Prozedur ist der Unit "mRSATools.pas" hinzuzufügen.
- Aus zwei solchen Pseudo-Primzahlen müssen wir dann die RSA-Schlüssel (n, e) und (d) generieren. Ein entsprechendes Programm soll diese Schlüssel herstellen können und uns erlauben, sie zu testen.
- Schließlich brauchen wir noch das eigentliche Benutzer-Programm ("RSACoDec.exe"), das in einem "Klartext-Fenster" einen Text entgegennimmt und ihn auf Knopfdruck verschlüsselt in einem "Geheimtext-Fenster" ausgibt. Ein zweiter Knopf soll umgekehrt den Text im Geheimtext-Fenster entschlüsseln und den dekodierten Text im "Klartext-Fenster" ausgeben. Das eigentliche Problem dabei ist: wie transformieren wir Texte in Zahlen und umgekehrt?
- Wenn wir ein (im Prinzip) praxistaugliches "RSACoDec"-Programm erstellen wollen, müssen wir auch noch die Schlüsselerzeugung sowie ein Schlüsselmanagement für die öffentlichen Schlüssel aller unserer Kommunikationspartner einbauen. Bei professionellen Lösungen wird die Schlüsselerzeugung üblicherweise in die Installationsroutine des Programms integriert. Wir wollen uns hingegen damit begnügen, auch die Erzeugung des eigenen RSA-Schlüssels in das Benutzerprogramm einzubauen, selbst wenn diese nur einmal gebraucht wird.
Glücklicherweise sind zumindest die ersten dieser Aufgaben einigermaßen unabhängig voneinander, so dass wir hier arbeitsteilig vorgehen können. Die folgenden Abschnitte enthalten die genauen Aufgabenstellungen und (soweit nötig) Hilfen zur Lösung.
5.2 Die Modulo-Exponentiation
Exponentieren ist als mehrfaches Multiplizieren definiert: für zwei natürliche Zahlen g und h ist gh = g*g*g*....*g, wobei das Produkt h Faktoren hat. Führt man die Berechnung der Potenz nach diesem Ansatz durch, sind also (h-1) Multiplikationen mit g nötig. Bei großen Werten von h führt dies zu inakzeptabel langen Laufzeiten. Der Algorithmus der "schnellen Exponentiation" reduziert den Aufwand deutlich. Die Grundidee dabei ist die folgende:
Zunächst wird der Exponent h in seine Binärdarstellung zerlegt:
h = h0*20 + h1*21 + h2*22 + h3*23 + ..... + hk*2k
wobei die hi nur die Werte 0 und 1 annehmen können. Schreibt man sich nun die Potenz nochmals hin, kann man sie wie folgt umformen:
gh = g(h0*20 + h1*21 + h2*22 + h3*23 + ..... + hk*2k)
= g(h0*20) * g(h1*21) * g(h2*22) * g(h3*23) * ..... * g(hk*2k)
= [g(20)]h0 * [g(21)]h1 * [g(22)]h2 * [g(23)]h3 * ..... * [g(2k)]hk
Schaut man sich diesen Produkt-Term genauer an, dann fällt folgendes auf:
- Die äußeren Exponenten hi können jeweils nur die Werte 0 oder 1 annehmen. Sie entscheiden damit also lediglich darüber, ob der entsprechende Faktor des Produkts den Wert 1 hat (falls hi = 0 ist) oder den in der eckigen Klammer enthaltenen Wert (falls hi = 1 ist).
- Die inneren Exponenten sind Zweierpotenzen, so dass sich für die Folge der Werte in den eckigen Klammern eine spezielle Serie von Potenzen von g ergibt: g0, g1, g2, g4, g8, g16,.... usw. Die Serie dieser Zahlen lässt sich leicht durch fortgesetztes Quadrieren erzeugen; z.B. ist g16 = g(8*2) = (g8)2.
Damit ist gh also darstellbar als ein Produkt aus "iterierten Quadraten von g", wobei die Binärstellen von h als Indikatoren dafür dienen, ob mit der aktuellen g-Potenz multipliziert werden muss oder nicht. Statt der ursprünglich benötigten h Multiplikationen sind nun nur noch höchstens so viele nötig, wie die Zahl h Binärstellen hat, nämlich etwa [2log(h)].
Genau genommen braucht man doppelt so viele Multiplikationen, denn zu den oben berücksichtigten für die Berechnung des Ergebnisses kommen nochmals genau so viele hinzu zur Berechnung der Serie der "iterierten g-Quadrate". Wenn wir aber weiter annehmen, dass die Binärdarstellung von h im Mittel genau so viele Nullen wie Einsen enthält, ist zu erwarten, dass wir für die eigentliche Berechnung des Ergebnisses im Durchschnitt schon mit halb so vielen Multiplikationen auskommen werden wie oben angegeben, weil das bisher errechnete Zwischenergebnis ja nur dann wirklich multipliziert werden muss, wenn die aktuelle Binärstelle eine "1" ist! Damit ist die zu erwartende Anzahl der Multiplikationen etwa [1.5 * 2log(h)].
Für das RSA-Verfahren brauchen wir ja gar nicht die ganze Potenz (gh), sondern nur ((gh) MOD n). Wegen (x*y*z) MOD n = (((x*y) MOD n) * z) MOD n kann man in der obigen Berechnung das Ergebnis jeder einzelnen Multiplikation mit dem Modul n reduzieren. Damit bleiben die zu handhabenden Zahlen stets kleiner als dieser Modul, was sich lohnt, selbst wenn nun zu jeder Multiplikation noch eine Division hinzukommt. Das folgende Bild ist dem schönen Buch "Informatik mit Delphi" von Eckart Modrow entnommen und zeigt ein Struktogramm des Algorithmus' der "schnellen Exponentiation":
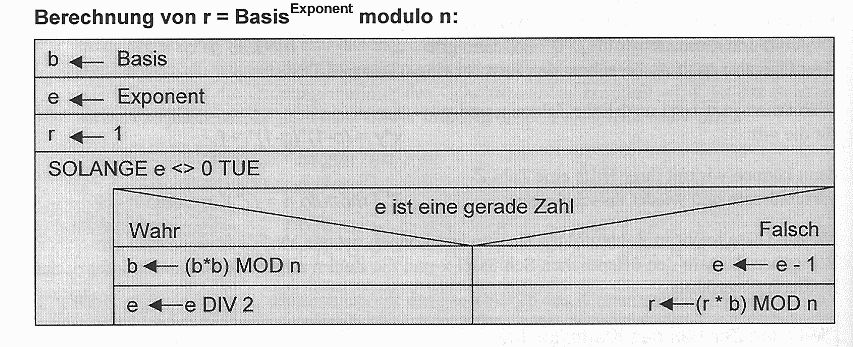 (aus: Eckart Modrow, "Informatik mit Delphi", Dümmler 2000, S. 98)
(aus: Eckart Modrow, "Informatik mit Delphi", Dümmler 2000, S. 98)
Aufgabe:
-
Die schnelle Exponentiation
Erzeugen Sie ein neues Projekt, das unsere TVLInt-Bibliothek benutzt. Implementieren Sie dann in einer Unit "mRSATools.pas" eine Prozedur "ExpMod(basis, expo, modul, wert: TVLInt)", die im letzten übergebenen Parameter wert das Ergebnis der Berechnung (also basis^expo MOD modul) zurückliefert, die drei ersten Parameter jedoch ungeändert lässt.
5.3 Das Problem der großen Primzahlen
Ob eine große ungerade Zahl p eine Primzahl ist oder nicht, kann man entscheiden, wenn man sie durch alle Primzahlen teilt, die zwischen 2 und SQRT(p) liegen. Ist p durch keinen dieser Testteiler ohne Rest teilbar, dann ist p sicher prim. Für hinreichend große p wird man in der Regel aber keine genügend umfangreiche Primzahltabelle mehr zur Verfügung haben. Wir müssen uns also darauf beschränken, mit einer festen Primzahltabelle zu arbeiten. Wenn wir auf diese Art und Weise keinen Teiler von p gefunden haben, dann ist p zumindest mal ein "heißer Kandidat" für eine Primzahl.
Ein Beweis für die Prim-Eigenschaft von p ist also auf diesem Wege nicht zu führen. Ersatzweise können wir p aber einem "probabilistischen Primzahl-Test" unterziehen. Wenn p den Test besteht, dann ist es wahrscheinlicher geworden, dass p eine Primzahl ist. Wohlgemerkt, beweisen können wir die Primzahl-Eigenschaft so nicht! Für den praktischen Einsatz genügt es uns aber, dass die Irrtumswahrscheinlichkeit für die Aussage "p ist prim" hinreichend klein gemacht werden kann.
Konkret benutzen wir den Miller-Rabin-Test. Dies ist ein Algorithmus, dem ein "heißer Kandidat" p und ein (natürlicher) "Sicherheits-Parameter" t (>= 1) übergeben wird. Zurückgeliefert wird dann ein bool'scher Wert, der angibt, ob n den Test bestanden hat oder nicht. Dabei gilt der "Satz von Miller und Rabin":
- Wenn p den Miller-Rabin-Test mit dem Sicherheitsparameter t nicht besteht, dann ist p sicher zerlegbar, also nicht prim.
- Wenn p den Miller-Rabin-Test mit dem Sicherheitsparameter t besteht, dann ist die Wahrscheinlichkeit, dass p trotzdem nicht prim ist, kleiner als 0,25t.
Wir können also die Wahrscheinlichkeit dafür, dass p eine Primzahl ist, durch einen großen Wert von t beliebig dicht an "1" heranführen - wodurch sich allerdings die Laufzeit des Tests entsprechend erhöht.
Sollten Sie grundsätzliche Bedenken haben gegen dieses Vorgehen, dann machen Sie sich klar, dass wir in den allermeisten Situationen des Alltags ebenfalls auf wirkliche Sicherheit verzichten! Meist geben wir uns mit einer genügend großen Wahrscheinlichkeit für das Eintreten eines erwünschten Ereignisses durchaus zufrieden: z.B. ist die Wahrscheinlichkeit, dass Sie beim Überqueren einer Straße nicht überfahren werden, deutlich kleiner als "1"! Trotzdem gehen Sie über die Straße....
Wie sieht nun dieser Miller-Rabin-Test eigentlich aus? Die zahlentheoretischen Hintergründe überlassen wir den Mathematikern, uns interessiert hier nur der Algorithmus. Im "Handbook of Applied Cryptography" von Menezes/Oorschot/Vanstone findet man die folgende Darstellung:
 (aus: Alfred J. Menezes et all, "Handbook of Applied Cryptography", CRC Press LLC 1997, S.139)
(aus: Alfred J. Menezes et all, "Handbook of Applied Cryptography", CRC Press LLC 1997, S.139)
Aufgabe:
-
Die mühsame Suche nach großen Primzahlen
Erzeugen Sie ein neues Projekt, das unsere TVLInt-Bibliothek benutzt. Implementieren Sie dann in einer Unit "mRSATools.pas" eine Prozedur "MillerRabinPrim(iw: Double; start, result: TVLInt)", die in result eine Zahl zurückliefert, welche mindestens so groß ist wie start und mit einer Wahrscheinlichkeit von mindestens (1 - iw) eine Primzahl ist. (Die Variablenbezeichnung "iw" soll an "Irrtumswahrscheinlichkeit" erinnern!)
Bevor Sie eine vermutete Primzahl dem eigentlichen Miller-Rabin-Test unterziehen, sollten Sie sicherstellen, dass diese Zahl durch keine der "kleinen" Primzahlen unserer schon früher erstellten Tabelle teilbar ist!
Noch ein kleiner Hinweis: es ist günstig, für den im Punkt 2.1 des obigen Algorithmus zu wählenden Parameter a beim ersten Durchgang tatsächlich den kleinstmöglichen Wert 2 zu nehmen, weil die meisten zusammengesetzten Zahlen beim Test mit a = 2 schon als "nicht prim" erkannt werden. Für die folgenden Belegungen von a kann man ohne Qualitätsverlust anstelle der im Algorithmus vorgeschlagenen Zufallszahlen die Serie der kleinsten ungeraden Primzahlen nehmen.
5.4 Die Schlüsselerzeugung
Da wir die mathematischen Hintergründe des RSA-Verfahrens schon an anderer Stelle ausführlich diskutiert haben, genügt hier eine kurze Wiederholung des Algorithmus' der Schlüsselerzeugung. Der öffentliche Schlüssel besteht aus zwei Zahlen n und e, der private Schlüssel ist eine Zahl d. Zur Schlüsselerzeugung geht man folgendermaßen vor:
- Zunächst wählt man zwei große (Pseudo-)Primzahlen
p und q.
- Als nächstes berechnet man den Modul n als das Produkt dieser beiden Primzahlen:
n = p * q.
- Dann bestimmt man die Hilfszahl Φ als das Produkt von (p-1) und (q-1):
Φ = (p-1) * (q-1)
- Nun wird der öffentliche Schlüssel e aus dem Intervall [2..Φ-1] so gewählt, dass es keine gemeinsamen Teiler mit Φ hat. Üblicherweise nimmt man ein recht kleines e, z.B. mit zwei oder drei Dezimalen.
- Der geheime Schlüssel ist schließlich eine Zahl d aus dem Intervall [2..Φ-1] mit der Eigenschaft, dass das Produkt aus d und e bei Division durch Φ den Rest 1 lässt.
Lediglich der letzte Schritt ist ein wenig trickreich. Eine "Brut-Force-Suche" nach einem passenden d kann bei großen Modulen etwas aufwändig werden. Es empfiehlt sich daher, ein wenig raffinierter vorzugehen und die Serie der Zahlen (k * Φ + 1) mit k = 1, 2, 3,... auf Teilbarkeit durch e zu untersuchen. Hat man ein kt gefunden, so dass (kt * Φ + 1) durch e teilbar ist, dann lässt sich das gesuchte d leicht als der Komplementärteiler zu e errechnen: d = (kt *Φ + 1) div e
Aufgabe:
-
Wir feilen einen RSA-Schlüssel...
Erzeugen Sie ein neues Projekt, das unsere TVLInt-Bibliothek und die "RSA-Tools" benutzt. Schreiben Sie ein Programm, das nach Eingabe der Anzahl der Dezimalstellen für die Primzahlen p und q einen kompletten Satz von RSA-Schlüsseln erzeugt, so wie es oben beschrieben ist.
Um Ihre neu erzeugten Schlüssel zu testen, wählen Sie eine beliebige Zahl m aus dem Bereich [1..n-1], verschlüsseln Sie sie (c = m^e MOD n) und entschlüsseln Sie das Ergebnis wieder (u = c^d MOD n). Ihr "RSA-Codec" ist korrekt, wenn sich immer u = m ergibt.
5.5 Anwendung auf Texte
Die zahlen-technische Seite des RSA-Problems ist nun abgearbeitet. Allerdings können wir bisher nur recht kurze "Nachrichten" in einem seltsamen Format verarbeiten: die "Nachricht" muss eine Zahl m sein, die kleiner ist als der Modul n des öffentlichen RSA-Schlüssels (n,e). Was aber, wenn m größer wird als n? Dann müssen wir die "Nachricht" eben in mehrere hinreichend kleine Abschnitte aufteilen und jeden Abschnitt einzeln verschlüsseln!
Jetzt ist es aber höchste Zeit für die Anwendung auf echte Texte, damit die bisher geleistete Arbeit auch konkrete Früchte tragen kann. Um flexibel zu bleiben, wollen wir bei den Buchstaben alle 256 Werte des Typs Char zulassen. Die Grundidee ist einfach:
- Bei der Kodierung übersetzen wir zunächst die Buchstabenfolge der gesamten Nachricht in eine Serie von TVLInt-Zahlen; dann wenden wir die RSA-Verschlüsselung auf diese Zahlen an; die so berechneten TVLInt-Zahlen bilden den Geheimtext.
- Bei der Dekodierung wenden wir zunächst die RSA-Entschlüsselung auf die Serie der TVLInt-Zahlen im Geheimtext an. Die entschlüsselten TVLInt-Zahlen werden dann zurückübersetzt in die zugehörige Buchstabenfolge der Nachricht.
Schauen wir uns das Vorgehen im Einzelnen noch etwas genauer an:
Wenn die zu verschlüsselnde Nachricht in einer Memo-Komponente vorliegt, ist sie dort in einzelnen Zeilen organisiert. Damit wir uns nicht zusätzlich noch mit der Zeilenverwaltung herumplagen müssen, packen wir zunächst den ganzen Text in eine einzige (lange) String-Variable m:
m := Memo1.Text;
Bei einem einfachen Text sind die Zeilenumbrüche dann als Steuerzeichen (genauer: #13#10-Zeichenpaare) in diesem String enthalten. Da wir alle ASCII-Zeichen zugelassen haben, ist dies problemlos möglich. Also reduziert sich unser Problem nun darauf, einen einzigen - allerdings möglicherweise recht langen - String m in eine Serie von TVLInt-Zahlen zu kodieren. Wir haben schon gesehen, dass wir m dazu möglicherweise in kleinere Teile s zerlegen müssen, um diese dann einzeln zu kodieren.
Der eigentliche Kern dieser Umsetzung hinreichend kleiner Teile s der Nachricht in entsprechende TVLInt-Zahlen soll in einer Prozedur
GetVLIntFromString(s: String; wert: TVLInt);
geschehen, die die Zeichen des Strings s eins nach dem anderen ausliest und die jeweilige ASCII-Nummer in der TVLInt-Zahl wert kodiert. Hierbei wird vorausgesetzt, dass der String s nur so viele Zeichen enthält, wie in wert "passen". Jeder von dieser Prozedur hergestellte TVLInt-Wert wird dann mit dem öffentlichen RSA-Schlüssel verschlüsselt, was wiederum eine TVLInt-Zahl liefert. Die Serie dieser RSA-verschlüsselten Zahlen ist die verschlüsselte Botschaft: der Geheimtext wird nun einfach aus den Dezimaldarstellungen all dieser Zahlen gebildet, wobei es sinnvoll ist, jede TVLInt-Zahl in eine eigene Zeile zu schreiben.
Diesen Geheimtext denken wir uns nun an den Empfänger geschickt, der dann die Dekodierung entsprechend umgekehrt abwickelt: zunächst wird aus jeder Zeile des Geheimtextes eine TVLInt-Zahl hergestellt. Der Empfänger entschlüsselt diese dann mit seinem privaten RSA-Schlüssel. Dabei entsteht wieder genau die TVLInt-Zahl, die der Absender aus den ASCII-Nummern der Zeichen in der ursprünglichen Nachricht gebildet hat. Diesen Vorgang müssen wir nun noch rückgängig machen, was in einer Prozedur
GetStringFromVLInt(wert: TVLInt; var s: String);
geschehen soll. Die dekodierten Strings werden dann hintereinander gehängt und schließlich als langer String dm ("d"ecoded "m"essage) in einer Memo-Komponente angezeigt:
Memo3.Text := dm;
Dann erscheint dort die dekodierte Nachricht - und wenn Sie alles richtig gemacht haben, stimmt Sie in Inhalt und Form Zeichen für Zeichen mit der ursprünglichen Nachricht überein! Das folgende Bild gibt nochmals einen Überblick über den Algorithmus:
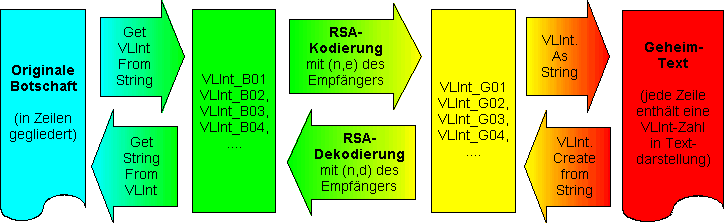
Algorithmus zur Kodierung (oben) und Dekodierung (unten)
eines Textes mit Hilfe von TVLInt-Zahlen
Zu klären ist nun aber noch, wie man sinnvollerweise Buchstabenreihen bijektiv auf (lange) Zahlen abbildet. Da gibt es natürlich viele Möglichkeiten. Die vielleicht naheliegendste Variante ist, dass man die ASCII-Nummern der einzelnen Zeichen des zu kodierenden Strings einfach dezimal hintereinanderschreibt: so würde z.B. das Wort "InFo" kodiert in der Zahl z = 73110070111, weil die dezimalen Zahlen 73, 110, 70 und 111 die ASCII-Nummern der Buchstaben "I", "n", "F" und "o" sind. Beachten Sie, dass innerhalb der Zahl jede hinzuzufügende ASCII-Nummer auf 3 Stellen "aufgeplustert" werden muss, wie das Beispiel des "F" lehrt. Dies gilt eigentlich auch für die "73", die das "I" darstellt. Aber führende Nullen werden bei jeder Zahldarstellung unterdrückt, sodass wir also zunächst nicht sicher wissen, wieviele der führenden Stellen der Zahl zur ASCII-Nummer des ersten Zeichens gehören.
Machen Sie sich klar, dass man die ASCII-Nummern in der obigen Zahl z als Ziffern einer Stellenwert-Darstellung zur Basis 1000 interpretieren kann:
z = 73 * 10003 + 110 * 10002 + 70 * 10001 + 111 * 10000
Um nun einer solchen Zahl z noch eine weitere ASCII-Nummer a hinzuzufügen, müssen alle schon existierenden Stellen um eine Tausender-Stelle nach links geschoben und dann das neue a hinzugezählt werden:
z := z * 1000 + a
Bei der Dekodierung kann die Extraktion der letzten ASCII-Nummer a dann entsprechend mit
a := z MOD 1000
geschehen, das anschließende Streichen der abgearbeiteten Stelle mit
z := z DIV 1000
Wenn Sie diese Schritte zur Berechnung und Interpretation der Zahlen z benutzen, werden die oben angedeuteten Probleme mit "kurzen" ASCII-Nummern vermieden.
Wie viele Buchstaben passen denn nun eigentlich in eine TVLInt-Zahl z hinein, wenn diese dabei kleiner bleiben soll als der Modul n? Es sei k die Anzahl der Dezimalstellen von n. Die maximal mögliche Buchstabenzahl maxL scheint zunächst die Anzahl der vollständigen Dreiergruppen von Ziffern in der Dezimaldarstellung von n zu sein, also (k DIV 3). Wenn allerdings k durch 3 teilbar ist, dann kommt es auf den Wert der vordersten 1000er-Stelle von n an: diese Stelle ist nur dann voll brauchbar, wenn sie mit einer "Tausender-Ziffer" größer als 256 besetzt ist. Man ist also in jedem Fall auf der sicheren Seite, wenn man maxL = k div 3 - 1 wählt.
Aufgaben:
-
Texte entschlüsseln....
Das ZIP-Archiv "Text_RSA" enthält ein Programmfragment. Dieses sollen Sie zu einem vollständigen Ver- und Entschlüsselungsprogramm für Texte ausbauen, das nach den oben beschriebenen Algorithmen arbeitet. Im Memo-Feld Memo1 soll dann später die zu verschlüsselnde Nachricht, in Memo2 der verschlüsselte Text und in Memo3 die wieder entschlüsselte Nachricht stehen. Kodierung und Dekodierung werden durch entsprechende Knöpfe ausgelöst, deren Klick-Prozeduren allerdings zunächst noch fehlen bzw. (fast) leer sind.
Dafür enthält das Programm einen vollständigen RSA-Schlüsselsatz (n, e, d) in Form von 3 String-Konstanten n_str, e_str und d_str. In der OnCreate-Prozedur des Formulars werden nicht nur entsprechende TVLInt-Zahlen hergestellt, sondern auch gleich noch die oben beschriebene Zahl maxL berechnet. Die Memo-Komponente Memo2 enthält darüberhinaus noch einen nach dem oben beschriebenen Verfahren verschlüsselten Text, der mit Hilfe des gegebenen öffentlichen RSA-Schlüssels verschlüsselt wurde. Dabei enthält jede Zeile dieses Geheimtextes genau eine RSA-kodierte TVLInt-Zahl.
Schreiben Sie zunächst in der Unit mRSATools die Prozedur GetStringFromVLInt(wert: TVLInt; var s: String). Implementieren Sie dann die Klick-Prozedur des Dekodier-Knopfes. Testen Sie Ihre Dekodierung, indem Sie sie auf den Text in Memo2 anwenden! Wenn sich in Memo3 ein sinnvoller Text ergibt, dann haben Sie gewonnen!
-
...und verschlüsseln
Wenn Sie die vorige Aufgabe erfolgreich erledigt haben, stellen Sie eine Kopie des Projekts her und implementieren Sie dann die Verschlüsselung.
Implementieren Sie dazu in der Unit mRSATools die Prozedur GetVLIntFromString(s: String; wert: TVLInt) und schließlich die Klick-Prozedur des Kodierungs-Knopfes. Testen Sie Ihren "RSA-Codec für Texte" mit verschiedenen Nachrichten. Wählen Sie aufgrund der doch erheblichen Rechenzeiten zunächst keine gar zu langen Texte.
Formulieren Sie Ihre Kritik an dem bisher implementierten Verfahren. Welche Unzulänglichkeiten sehen Sie noch? Haben Sie Lösungsansätze?
5.6 Aus Fehlern soll man lernen...
Die Ergebnisse des vorigen Kapitels sind doch einigermaßen ernüchternd. Zwar war der betriebene Aufwand erheblich, aber was wir erreicht haben, ist in zumindest zweierlei Hinsicht unbefriedigend:
- Die produzierten Geheimtexte sind ziemlich umfangreich.
- Der Entschlüsselungsvorgang ist auffällig langsam.
Wir wollen diese beiden Punkte etwas genauer anschauen:
- Dass der Geheimtext stets deutlich länger ist als die originale Nachricht, ist leicht einzusehen: während für die Darstellung der Nachricht das ganze ASCII-Alphabet mit seinen 256 Zeichen benutzt wird, nehmen wir für die Darstellung des Geheimtextes nur das Alphabet aus den 10 Ziffern! Also trägt ein Zeichen der ursprünglichen Nachricht die Informationsmenge 8 Bit, während die meisten Zeichen des Geheimtextes nur etwa 3½ Bit transportieren, das führende Byte einer Dreiergruppe sogar weniger als 2 Bit!
Eine kleine Verbesserung ergibt sich, wenn man in den oben konstruierten Tranfer-Funktionen GetVLIntFromString und GetStringFromVLInt statt der Basis 1000 nur die Basis 256 benutzt. Die spart pro kodiertem Zeichen immerhin 2 Bit. Aber damit ist das Problem natürlich noch nicht gelöst!
-
Der zweite Kritikpunkt ist noch gravierender: die Entschlüsselung ist definitiv langsam, und die Modulo-Exponentiation mit dem riesigen Exponenten des privaten Schlüssels lässt sich kaum wesentlich beschleunigen. Natürlich ist unsere Implementierung der TVLInt-Zahlen sicher noch deutlich vom Optimum entfernt, aber selbst eine Reduzierung der Rechenzeit auf 10% der aktuell benötigten (- ein größerer Fortschritt ist kaum drin! -) verlagert das Problem nur hin zu etwas größeren Texten!
Wir wollen uns zunächst einmal diesem zweiten Problem zuwenden. Wie machen das denn eigentlich die Profis? Phil Zimmermann, der Autor von "Pretty good privacy", einem bekannten RSA-basierten Verschlüsselungsprogramm, benutzt in seiner Software ein zweistufiges Verfahren: die eigentliche Nachricht wird mit einem symmetrischen Verfahren verschlüsselt, das eine sehr schnelle Kodierung und Dekodierung erlaubt. Der verwendete Schlüssel Ksym wird dabei unter Verwendung von Zufallszahlen für jede Nachricht neu erzeugt und mit der Nachricht an den Empfänger gesendet - allerdings natürlich nicht im Klartext, sondern mit dem öffentlichen RSA-Schlüssel des Empfängers verschlüsselt! Der Empfänger entschlüsselt dann mit seinem privaten RSA-Schlüssel diesen symmetrischen Schlüssel Ksym und verwendet ihn schließlich zur Entschlüsselung des Geheimtextes. Dabei hängt wenig von der konkret verwendeten Art der symmetrischen Verschlüsselung ab, solange nur hinreichend lange Schlüssel verwendet werden. Man kann also getrost einen einfachen (und damit schnellen) Algorithmus wählen, ohne dass die Sicherheit des Verfahrens leidet: diese wird durch das RSA-Verfahren garantiert, das den symmetrischen Schlüssel vor den Augen eines Dritten verbirgt!
Wenn wir uns an dieser Idee orientieren, müssen wir also ein symmetrisches Verschlüsselungsverfahren für die Kodierung der eigentlichen Nachricht implementieren. Der einfachste Algorithmus ist wohl das XOR-Verfahren. Die logische Verknüpfung XOR zweier Bits ist genau dann "1", wenn die beiden Bits verschiedene Werte haben. Man hat also die folgende Verknüpfungstafel:
Wenn man nun zwei Byte-Werte miteinander XOR-verknüpft, dann wird diese Operation bitweise ausgeführt. Zum Beispiel:
182 XOR 170 = (1011 0110)b XOR (1010 1010)b = (0001 1100)b = 28
Wenn man nun aber dieses Ergebnis nochmals mit 170 XOR-verknüpft, dann erhält man:
28 XOR 170 = (0001 1100)b XOR (1010 1010)b = (1011 0110)b = 182
also die ursprüngliche Zahl! Dieser Effekt ist das Rückgrat der XOR-Verschlüsselung: wenn wir 182 als ein Byte der Nachricht interpretieren und 170 als den Schlüssel, dann ist 28 das kodierte Byte des Geheimtextes. Und man erhält aus dem Geheimtext-Byte 28 das zugehörige Klartext-Byte 182, indem man auf 28 einfach dieselbe XOR-Operation nochmals anwendet. Entschlüsseln mit XOR ist also dasselbe wie Verschlüsseln mit XOR! Mathematiker sagen dazu: XOR ist eine involutorische Operation, was bedeuten soll, dass sie ihr eigenes Inverses ist. Kennen Sie eine Abbildung aus der Geometrie mit dieser Eigenschaft?
Für den besseren Überblick ist in den beiden folgenden Grafiken dargestellt, wie die verschiedenen Konvertierungs-Algorithmen beim derzeit angestrebten Zustand unseres Projektes zusammenarbeiten sollen. Zunächst zur Verschlüsselung:
Und nun die Entschlüsselung entsprechend "umgekehrt":
Aufgaben:
-
Symmetrisch geht es schneller....
Gehen Sie von dem Zustand unseres Projektes aus, der am Ende der vorigen Aufgabe erreicht worden war. Erweitern Sie zunächst unsere TVLInt-Zahlen, indem Sie die Operation XOR implementieren. (Sie ist für Integerzahlen in Delphi verfügbar.) Beachten Sie dabei, dass für c = a XOR b im Ergebnis c genau so viele Stellen zu berechnen sind, wie die größere der beiden Zahlen a und b Stellen hat. Erst nach der vollständigen Berechnung können Sie eventuell führende Nullen wegstreichen.
Ergänzen Sie nun das Programm so, dass es beim Start eine TVLInt-Zahl erzeugt, die als symmetrischer Schlüssel Ksym verwendet werden kann. Bauen Sie das Programm dann so um, dass statt der RSA-Ver- und Entschlüsselung eine XOR-Ver- und Entschlüsselung verwendet wird.
-
...und trotzdem sicher!
Wenn Sie die vorige Aufgabe erfolgreich erledigt haben, stellen Sie eine Kopie des Projekts her und ergänzen Sie dann das Management für den symmetrischen Schlüssel Ksym! Beim Verschlüsseln ist dem Geheimtext eine RSA-verschlüsselte Version von Ksym voranzustellen; beim Entschlüsseln ist zunächst durch RSA-Entschlüsselung Ksym wiederzugewinnen und dann damit die eigentliche Nachricht zu dekodieren. Überlegen Sie sich genau, wie Sie die Trennstelle zwischen Schlüssel und Text in der kodierten Nachricht markieren!
Überzeugen Sie sich davon, dass diese Version selbst größere Nachrichten recht flott abarbeitet.
5.7 Die base64-Kodierung
Nun ist nur noch ein Problem übrig: der Geheimtext ist nach wie vor viel zu lang! Um auch diesem Übel abzuhelfen, kann man auf die Idee kommen, den "Geheimtext" vor dem Versenden zum Empfänger wieder in einen "richtigen" Text zu verwandeln. Ehe wir also eine Zeile des Geheimtextes schreiben, sollten wir den String, der die TVLInt-Zahl darstellt, in einen "echten" Text zurückverwandeln. Die naheliegendste Idee könnte sein, dazu einfach die schon vorhandene Prozedur GetStringFromVLInt zu verwenden. Entsprechend müsste man dann bei der Dekodierung jede solche Buchstabenzeile des Geheimtextes erst mit einem Aufruf von GetVLIntFromString in einen numerischen String verwandeln, der eine TVLInt-Zahl darstellt.
Ein Problem dabei ist aber, dass die TVLInt-Zahlen des Geheimtextes recht chaotisch über das Intervall [1..n-1] verteilt sind, so dass in einem mit GetStringFromVLInt erzeugten String leider eine Menge Steuerzeichen stecken können. Damit ist der "Text" kein einfach transportierbarer Text mehr. Unsere bisherigen Transfer-Funktionen sind also für diesen Zweck ungeeignet.
a) Ein standardisiertes Kodierungsverfahren: base64
Dasselbe Problem hat man, wenn man einer EMail ein binäres Attachment anhängen will. EMail ist stets textbasiert, und darf (fast) keine Steuerzeichen enthalten. Andererseits kommen in binären Dateien eben auch solche Bytes vor, die - als ASCII-Nummern interpretiert - ein in diesem Sinne unzulässiges Zeichen darstellen. Man muss also die binären Daten so kodieren, dass dabei nur druckbare Zeichen verwendet werden. Dafür wurde schon 1993 ein Verfahren vorgeschlagen, das inzwischen zum Standard geworden ist, nämlich die base64-Kodierung. Diese Kodierung wird im "MIME"-Standard ("Multipurpose Internet Mail Extensions", siehe RFC 1521) für EMail-Anhänge aller Art verwendet.
Die Grundidee der base64-Kodierung ist, dass man eine beliebige Byte-Folge in ein Alphabet aus 64 druckbaren Zeichen kodiert. Wegen 64 = 26 kann ein Zeichen aus diesem Alphabet aber nur 6 Bit Information transportieren. Daher braucht man 4 solche Zeichen, um 3 Byte zu kodieren:
3 * 8 Bit = 24 Bit = 4 * 6 Bit
Man unterteilt also die zu kodierende Byte-Folge in Gruppen zu 3 Byte und kodiert diese dann in 4 Zeichen aus dem base64-Alphabet. Der Umfang der kodierten Nachricht ist daher immer 4/3 des Umfangs der originalen Byte-Folge, was dem aufmerksamen Beobachter beim Versenden von EMails mit Anhängen schon aufgefallen sein sollte.
Was macht man aber, wenn die Anzahl der Bytes in der Folge nicht durch 3 teilbar ist? Nun, dann könnte man der Folge vor der Kodierung entsprechend viele Null-Bytes anhängen. Die originale Definition des base64-Algorithmus verwendet stattdessen ein spezielles 65. Zeichen zur Kennzeichnung von Byte-Bestandteilen, die nicht mehr zur Nachricht gehören. (Wer allerdings ein wenig über dieses Problem nachdenkt, sollte bemerken, dass man auf solche speziellen Zusatzzeichen auch komplett verzichten kann, sofern man sich bei der Formulierung des Algorithmus' ein wenig Mühe gibt.)
Die Wahl des Alphabets ist eigentlich beliebig, solange es nur druckbare ASCII-Zeichen enthält. Will man aber eine MIME-konforme base64-Kodierung nach RFC 1521 implementieren, dann muss man sich nicht nur an das in diesem Dokument angegebene Alphabet halten, sondern auch alle weiteren dort beschriebenen Details der Kodierung beachten.
b) Umgang mit "untypisierten" Daten: Streams
Die base64-Kodierung wurde also entworfen, um beliebige binäre Daten in ein "email-taugliches" Textformat zu kodieren, und genau dies verlangen wir auch von einer universell anwendbaren base64-Implementierung. Dabei stellt sich jedoch die Frage, wie man eigentlich in Delphi mit "beliebigen binären" Daten umgeht. Object Pascal ist eine typ-strenge Sprache, in der "untypisierte" Daten eigentlich unerwünscht sind. Glücklicherweise gibt es aber aus historischen Gründen noch eine Klasse, die diese Aufgabe elegant löst, nämlich TStreams. Ein "Stream" ist eine Schlange beliebiger Daten, die sequenziell geschrieben und wieder gelesen wird. Der Stream hat eine Länge ("Size"), und der Lese- bzw. Schreibkopf steht stets an einer bestimmten Stelle ("Position"). Die Lese- und Schreib-Operationen sind in den Methoden "Read" und "Write" implementiert; diese müssen neben der Angabe der Quell- bzw. Zielvariablen auch noch die Anzahl der zu schreibenden bzw. zu lesenden Bytes als Parameter übergeben bekommen.
Wenn Sie nun vermuten, dass Streams wohl so ähnlich "funktionieren" wie Dateien, dann haben Sie nicht unrecht: strukturell gibt es da große Ähnlichkeiten. Es gibt in Delphi einige vordefinierte Stream-Varianten, z.B. den "FileStream", der sich dann tatsächlich leicht in eine Datei schreiben lässt, aber auch den "MemoryStream", der nur im RAM des Rechners "lebt" und damit die für uns hier wohl interessanteste Version ist. Weitere Details über Streams finden Sie in der Delphi-Hilfe.
Aufgabe:
-
Panta rhei....
Implementieren Sie in einer eigenen Unit "xxcode.pas" eine Klasse "TXXCoDec", die eine base64-Kodierung zur Verfügung stellt. Wie eng Sie sich dabei an die in RFC 1521 niedergelegten Vorgaben halten, bleibt Ihnen überlassen. Überlegen Sie sich zunächst, welche Aufgaben erledigt werden müssen, und was ein Benutzer von dieser Klasse erwartet.
Auf jeden Fall sollten Sie zwei Methoden EncryptStream2XXString(MS: TStream; var s : String) und DecryptXXString2Stream(s: String; MS: TStream) implementieren, die die Kodierung bzw. Dekodierung beliebiger binärer Daten mit Hilfe von Streams erlauben.
Schreiben Sie sich eine Testumgebung, und überprüfen Sie die Funktionsfähigkeit Ihres "Base64CoDec". (Ein "CoDec" ist ein "Kodierer/Dekodierer", also ein Gerät, das Informationen von einer "Sprache" in eine andere und auch wieder zurück übersetzen kann.)
c) Und jetzt alle zusammen....
Nun können wir diese neue Kodierung in unserem Kryptographie-Projekt anwenden. Zunächst wird in der letzten Stufe der Verschlüsselung die Umsetzung der XOR-verschlüsselten VLInt-Zahlen in einen lesbaren Text nicht mehr mit der "VLInt.AsString"-Methode erledigt, sondern mit der oben beschriebenen Base64-Kodierung. Entsprechend übernimmt die Base64-Dekodierung das Auslesen der XOR-kodierten VLInt-Zahlen aus dem Geheimtext.
Aber es ist noch eine Vereinfachung des Algorithmus möglich: wenn wir bei der Verschlüsselung die Liste des TVLInt-Zahlen in einen Stream schreiben, dann kann dieser ja beliebige binäre Daten aufnehmen. Damit können wir uns aber die Umsetzung des Klartextes in dezimal dargestellte VLInt-Zahlen komplett ersparen und stattdessen die originale Botschaft Zeichen für Zeichen mit der Folge der Bytes unseres symmetrischen Schlüssels direkt XOR-kodieren. Zwar erhalten wir dabei möglicherweise auch Sonder- und Steuerzeichen, aber die nachfolgende Base64-Kodierung garantiert ja, dass der erzeugte Geheimtext stets ein "richtiger" Text ist und keine solchen unzulässigen Zeichen mehr enthält! Entsprechend verzichten wir bei der Dekodierung des Geheimtextes ebenfalls auf dessen Umsetzung in VLInt-Zahlen: die byte-weise XOR-Dekodierung der von der Base64-Dekodierung gelieferten Byte-Folge liefert direkt den gewünschten Klartext der Botschaft.
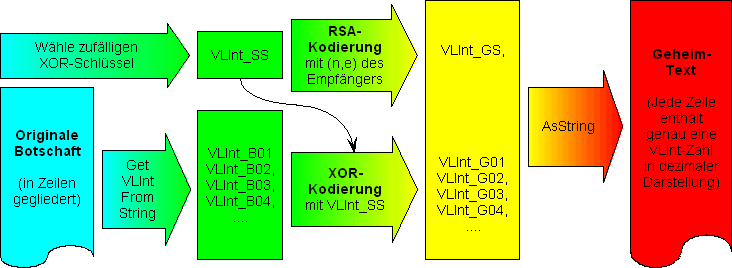
Da in den Algorithmen der Verschlüsselung und Entschlüsselung inzwischen also drei(!) verschiedene Kodierungsverfahren verwendet werden, ist es wohl angebracht, sich nochmals zu vergegenwärtigen, wie diese Algorithmen im Detail zusammenwirken. Beim Verschlüsseln gehen wir folgendermaßen vor:
- Die ganze zu kodierende Botschaft wird in einen (langen) String m zusammengefasst, der die Zeilenumbrüche als Steuerzeichen ("#13#10"- bzw. "$OD$OA"-Paare) enthält.
- Wir wählen einen zufälligen XOR-Schlüssel VLInt_SS. Dieser besteht aus einer VLInt-Zahl, die so viele Dezimalstellen hat wie der Modul n des RSA-Schlüssels des Empfängers.
- Der Schlüssel VLInt_SS wird RSA-kodiert mit dem öffentlichen Schlüssel des Empfängers der Nachricht; die dabei erhaltene TVLInt-Zahl VLInt_GS wird in den Stream geschrieben.
- Danach wird der Inhalt des Strings m Zeichen für Zeichen mit den Bytes des Schlüssels VLInt_SS XOR-kodiert; die erhaltenen Zeichen (bzw. Bytes) werden ebenfalls in den Stream geschrieben.
- Schließlich wird der gesamte Inhalt des Streams "in einem Rutsch" Base64-kodiert. Der dabei erzeugte String g enthält den Geheimtext.
- Schließlich wird der Inhalt von g nun noch durch Einfügen von Zeilenumbrüchen auf mehrere Zeilen verteilt.
Das folgende Bild zeigt die wesentlichen Schritte dieses Algorithmus nochmals "auf einen Blick":
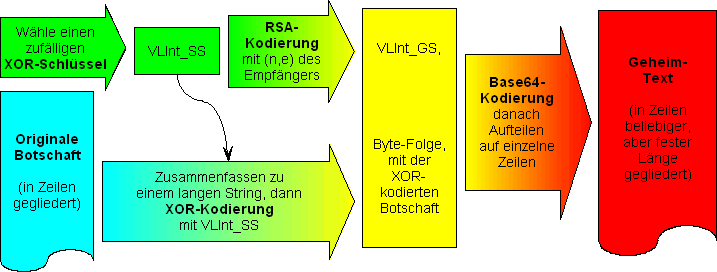 Kodierungs-Algorithmus
Kodierungs-Algorithmus
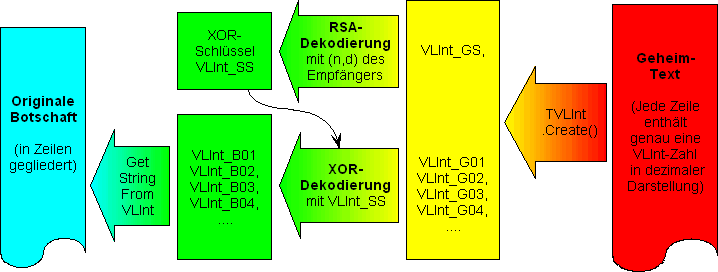
Das Entschlüsseln läuft dann entsprechend umgekehrt ab. Der einzig trickreiche Punkt ist, dass man vor der XOR-Dekodierung des Geheimtextes den XOR-Schlüssel VLInt_SS restaurieren muss. Dazu muss der Empfänger die TVLInt-Zahl VLInt_GS vom Anfang des Streams auslesen und sie mit seinem privaten RSA-Schlüssel dekodieren. Das folgende Bild zeigt den Dekodierungs-Algorithmus:
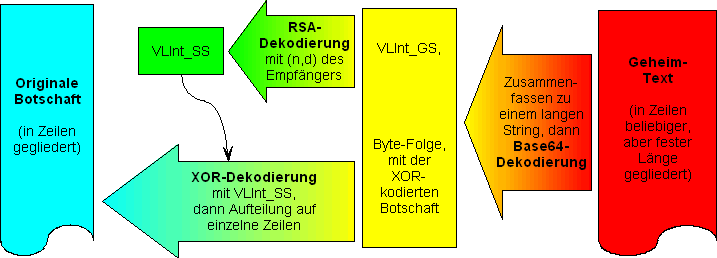 Dekodierungs-Algorithmus
Dekodierungs-Algorithmus
Aufgabe:
-
Die (vorläufig) letzte Version
Statten Sie nun unsere VLInt-Zahlen mit der Fähigkeit aus, dass sie ihre Daten in einen Stream schreiben und sie auch wieder aus dem Stream auslesen können. Die Grundidee ist, einfach die Serie der "Digits" in den Stream zu schreiben. Beachten Sie aber, dass VLInt-Zahlen sehr unterschiedliche Längen haben können. Und dann gibt es da auch noch das Vorzeichen, das zwar für uns derzeit keine Rolle spielt, aber bei einer so wichtigen Erweiterung der Klasse TVLInt nicht links liegen gelassen werden sollte!
Erweitern Sie das Programm nun so, dass der in Memo2 ausgegebene Geheimtext base64-kodiert ist. Schreiben Sie dazu einfach alle bei der RSA- bzw. XOR-Kodierung anfallenden TVLInt-Daten in einen (lokalen) Stream und lassen Sie diesen zum Schluss "in einem Rutsch" von einem Base64Codec in einen (eventuell sehr) langen String kodieren. Diesen können Sie nun in die Zeilen von Memo2 eintragen - mit einer frei wählbaren Zeilenlänge (z.B. 60 Zeichen pro Zeile).
Und natürlich muss dann auch noch die Dekodierung entsprechend ergänzt werden!
5.8 Finale furioso
Nun hat unser "RSACoDec"-Programm doch schon eine gewisse Reife erreicht: die ursprünglich gesetzten Ziele für die Verschlüsselung und Entschlüsselung sind erreicht. Allerdings fehlt für den praktischen Einsatz des Programms noch ein Management für die öffentlichen RSA-Schlüssel unserer Kommunikationspartner. Außerdem sollten wir auch noch eine Routine einbauen, die uns die Erstellung des eigenen RSA-Schlüssels erlaubt, sofern bisher noch keiner vorhanden ist.
Natürlich ist das Schlüsselmanagement eine klassische Datenbank-Aufgabe, bei der Fragen der Sicherheit besonders wichtig werden. Zumindest der eigene private RSA-Schlüssel ist ja wirklich schützenswert: wenn wir ihn wegwerfen oder durch einen neuen ersetzen, zerstören wir effektiv den sicheren Informationskanal zu allen unseren bisherigen Kommunikationspartnern! In professionellen Lösungen muss man also den privaten Schlüssel besonders gut schützen.
Wir wollen den Aufwand um die Schlüsseldaten nicht zu hoch treiben. Da es sich im vorliegenden Fall eher um eine Machbarkeitsstudie als um die Entwicklung eines ernsthaften Kryptographie-Programms handelt, begnügen wir uns damit, den eigenen Schlüssel in eine Textdatei ("private.key") zu schreiben und alle öffentlichen Schlüssel (auch unseren eigenen!) in eine zweite Textdatei ("public.key"). Wenn Sie ernsthaft daran interessiert sind, PGP Konkurrenz machen zu wollen, dann besteht Ihre erste Aufgabe darin, diese beiden Textdateien (oder zumindest die erste!) sicher zu verschlüsseln - z.B. mit einem programminternen RSA-Schlüssel! Alles was Sie dazu brauchen, haben Sie schon an Bord!
Um die Weitergabe unseres öffentlichen RSA-Schlüssels möglichst einfach zu machen, wählen wir für die Schlüsseldatei "public.key" ein schlichtes CSV-Format ("C"omma "S"eparated "V"alue). Dieses universelle Daten-Austauschformat kann von nahezu allen Datenbank-Programmen gelesen werden. Eine CSV-Datei enthält die Beschreibung einer Tabelle, in der die gewünschten Daten stehen. Für den Aufbau dieser Textdatei gelten die folgenden Regeln:
- Die erste Zeile enthält die Spaltenüberschriften der Tabelle.
- Jede weitere Zeile enthält einen kompletten Datensatz.
- Die einzelnen Daten in jeder Zeile werden als Text dargestellt und durch ein Semikolon (";") voneinander getrennt.
Beachten Sie, dass im Namen des Formats zwar das Wort "Comma" vorcommt, als Trennzeichen aber (in der Regel) das Semikolon verwendet wird. Achten Sie weiter darauf, dass am Ende einer jeden Datenzeile kein Semikolon steht!
Um die kommunikationsfähigkeit unseres Programms mit anderen gleichartigen sicherzustellen, legen wir für die Tabelle der öffentlichen Schlüssel fest, dass sie genau die folgenden vier Spalten enthalten soll:
- "Id" ist eine (laufende) Nummer, die den Datensatz eindeutig identifiziert
- "Name" ist der Name des Kommunikationspartners
- "n" ist der Modul seines öffentlichen RSA-Schlüssels
- "e" ist der Verschlüsselungs-Exponent seines öffentlichen RSA-Schlüssels
Damit ist der Aufbau der Datei "public.key" hinreichend festgelegt. Wie Sie Ihren privaten Schlüssel in der Datei "private.key" ablegen, soll hingegen komplett Ihnen überlassen bleiben. Beginnen Sie aber mal mit einem möglichst einfachen Format. Den Drang nach mehr Sicherheit können Sie dann später noch austoben, wenn Ihr "RSACoDec" dann erst mal rund läuft....
Aufgaben:
-
Was lange währt....
Fügen Sie die in den vorigen Abschnitten erarbeiteten Teillösungen nun zu einem funktional vollständigen Programm für RSA-verschlüsselte Kommunikation zusammen. Es soll die folgenden Funktionen beinhalten:
- Generierung und Speicherung eines eigenen RSA-Schlüsselpaares
- Import und Speicherung fremder RSA-Schlüssel
- Eingabe eigener Nachrichten
- Verschlüsselung dieser Nachrichten mit dem öffentlichen RSA-Schlüssel des Empfängers
- Aufnahme von Nachrichten von Anderen
- Dekodierung dieser Nachrichten